
Para esto necesitaremos tener instalado python +3 en nuestra pc/server/gato!
1 – Instalar python + pip
Vamos a https://www.python.org/downloads/ y descargamos la versión de nuestro SO, luego de descargarlo lo instalamos (el común y mas viejo: siguiente, siguiente siguiente)
Luego necesitaremos instalar pip, que es el encargado de instalar los paquetes de python que necesitemos, veremos el tutorial en:
2- Descargar / instalar Scraper / editar Scraper
Para esto utilizaremos el git de: https://github.com/eneiromatos/NebulaExpiredArticleHunter/ el cual nos permite descargar los post de los dominios caducados (usa el cache de web archive)
Una ves descargado en nuestro dispositivo, abrimos la consola, nos dirigimos a donde extrajimos el contenido del zip (ejemplo C:\Users\Cicklow\Desktop\NebulaExpiredArticleHunter\) y ponemos el comando:
El cual nos instalara las librerías necesarias que usa nebula!
Cuando ya tengamos instalado todas las librerías, realizaremos una edición al archivo scrapearticle.py, el cual lo editaremos para que nos sirva mejor.
Buscamos la función
Y la cambiamos por:
¿Por qué el edit?, es para tener más control sobre el contenido scrapeado y luego subirlo a donde lo necesitemos. Como vemos tenemos dos opciones, formato para blogger (no editemos ese…) u otro, este otro lo pueden editar a gusto.
3- Archivo encargado de subir nuestro post a blogger
Este archivo que crearemos, nos permitirá subir todo el contenido screapeado a blogger (usaremos blogger para crear backlinks hacia nuestro sitio real). y lo guardamos en la misma carpeta del nebula.
El código lo que hace es recorrer las carpetas donde el scraper guardo nuestros post, los pasa por el template, y luego usando easyblogger, los postea!
4- Obtener dominios caducados y scrapear
Para esto iremos a https://member.expireddomains.net/ (si no tenemos cuenta, nos creamos una, es gratis). Nos logeamos y buscamos la que necesitemos.
Ejemplo “software”, nos aparecerá un listado de dominios, y los ordenaremos por “ACR“, que son la cantidad de url en cache de WebArchive.org
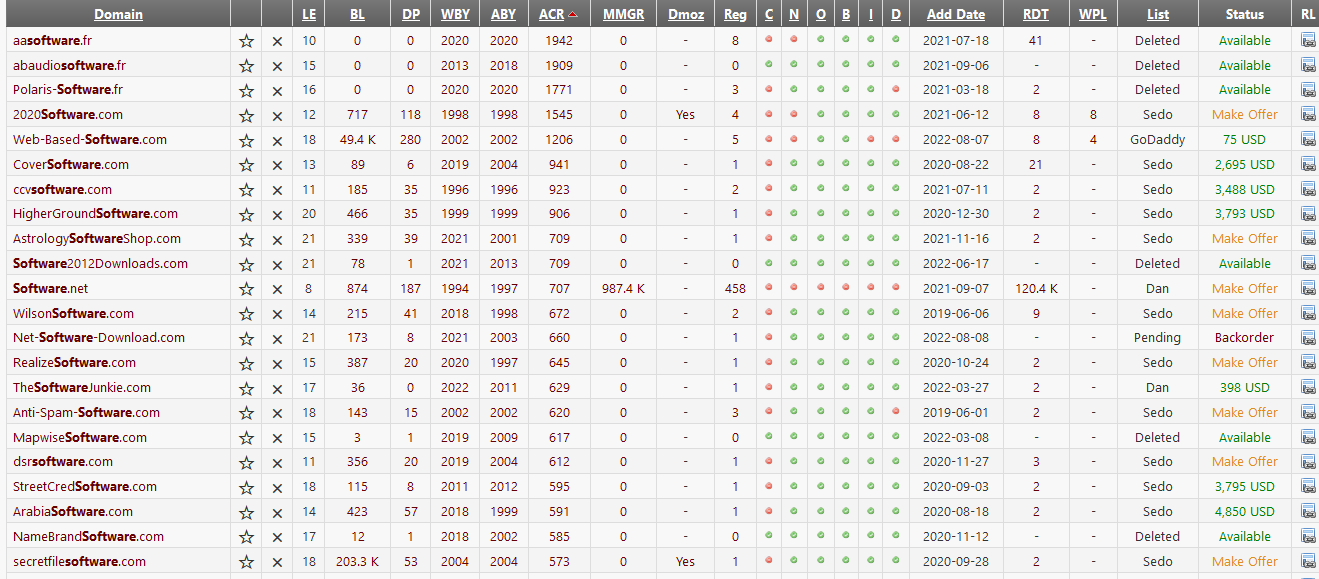
le damos click al botón copiar al portapapeles (esto nos copiara las 25url que tenemos en pantalla). Una vez copiadas las url, vamos a la carpeta del nebula, buscamos/creamos el archivo expired_domains.txt y agregamos las url.
Volvemos a la consola de nuestro SO. y ponemos el comando python main.py esto lo que hace es comenzar a descargar los post que tengan los sitios webs caducados. Los guarda todos en la carpeta projects/dominiocaducado.com
El script puede tardar bastante dependiendo de la cantidad de url cacheadas!.
5- Instalar easyblogger
Este script (easyblogger) lo que hace es permitirnos postear en blogger desde nuestra dispositivo. Para esto vamos a la consola de nuestro SO y ponemos:
Luego instalamos pandoc
Esperamos que termine y luego ejecutamos:
el lo obtenemos accediendo a nuestro blog (en blogger), viendo el código fuente y buscar algo como:
El cual 7642453 seria nuestro ID (ejemplo)
Volviendo a ejecutar el comando, el script nos abrirá una url en nuestro navegador el cual le daremos permiso a easyblogger para que controle nuestro blogger (cualquier problema con este script, el git tiene las instrucciones necesarias).
6- Subir nuestros post a blogger
Ahora ejecutaremos el archivo creado en el paso 3 con:
Si vemos en el paso 3, tenemos algunas opciones para editar
– Las keys y sus respectivas url
Acá cambiamos las keys junto a las url de nuestros blogs.
– Cantidad de cambios
Esta variable nos permitirá saber cuántos cambios hacemos respecto a las keys, por defecto es 1, o sea que la primer palabra que encuentre con nuestra key, sera reemplazada por la url de nuestro blog. Si ponemos 2, reemplazara 2 keys iguales, etc…
– Template para los links
Este template nos permitirá crear el formato de los links, no tiene mucho misterio, pero si es necesario agregar algo más al link, desde ahi pueden.
– Directorios donde sacar los artículos
Acá colocaremos los dominios/nombre de la carpeta, desde donde nuestro script sacara los artículos. Esto esta echo así porque el scraper por ahi junta muchas cosas que no necesitamos, ejemplo el post de las políticas de privacidad, contacto, esas cosas… Nos tendremos que tomar el trabajo, luego que el scraper termine, de ir recorriendo cada carpeta/dominio y sacar los post que no necesitemos.
-Template para los post en blogger
Este mini template le indicara a nuestro script cómo tendrán que ser los post en blogger. Ustedes pueden editarlo respetando las palabras a reemplazar (#IMAGEN#, #TEXTO#)… Pueden editar el script para que si el post no tiene imagen, coloque una por defecto en:
Al ejecutar el script, easblogger posteara todo en nuestro blog.
7- Otros CMS
Nuestro script esta echo para funcionar en blogger, pero podemos hacerlo funcionar en WP, para esto vamos a scrapearticle.py buscamos
y cambiamos el valor de esa variable (por cualquier cosa).
En WP usaremos el plugin https://wordpress.org/plugins/import-html-pages/ (ustedes usen el que gusten), lo configuramos indicando donde estarán los txt (tendremos que subir los txt a nuestro hosting), y como sacar el contenido… en nuestro ejemplo, le diremos que saque el titulo del post de entre <h1> y </h1> y el post desde <p> y </p> (todo esto se puede cambiar desde el archivo scrapearticle.py.
Le damos importar y tendremos un WP lleno de post, GRATIS!
Notas finales
Todo esto nos genera contenido GRATIS para nuestro sitio, o para obtener backlinks, no es del todo automático, pero nos sirve (hay soft pagos como article hunter, etc que hacen esto, pero, nosotros editamos a gusto y placer nuestro script).
Las ediciones o planes que tengan sobre esto, son suyas, ejemplo pueden buscar como modificar el texto para que no sea exacto a lo que hay, hacerles mejoras, etc… todo pueden hacerlo, siempre y cuando NO se les ocurra vender este tutorial como propio ni modificaciones del mismo!
Hay muchos script en github, es solo aprender a usarlo y agregarlos a nuestra programación (si, les tocara aprender a programar, aunque sea un poco).
Para todo esto, link de descarga (nebulahunter + script upload de blogger): https://mega.nz/file/amoRmALS#KVuqcW5bDXgUnzwjiUI-ohAELKSvE3ILNrcNy-m8TmQ





